Stochastic Gradient decent is one of the fundamental algorithm in deep learning. It is used when we perform optimization of the cost function.Suppose the function is $ f(x) $
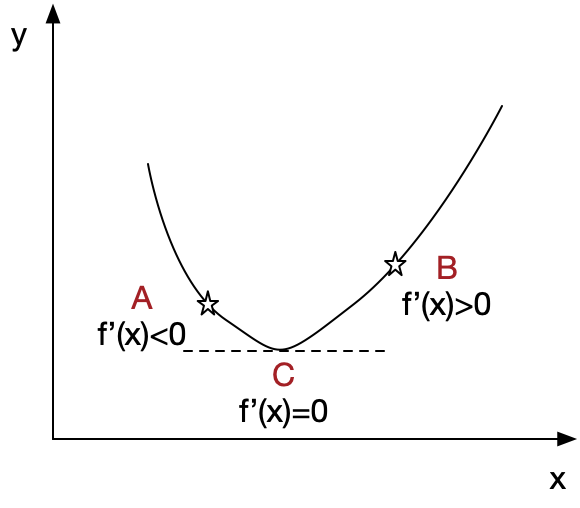
As what illustrated above, we want to approach the minimum value of f(x) which is the point C. If we are now at point A, the derivation of A is f’(x)>0, so we need to go right down which is the opposite direction of f’(x). If we stand at B,the derivation of A is f’(x)>0, we should go left down which is also the opposite direction of f’(x).
According to the optimization strategy , we should update the parameter like this: $$ x = x - \eta f’(x) $$ $\eta$ is so-called the learning rate, it determines the size of steps we take to reach a minimum value of $f(x)$
Batch Gradient
Follow the rules of gradient descent, when we perform one update of parameters the intuitive strategy is to calculate the gradients for all the examples in the dataset and sum them up, this computation process is also called batch gradient.
The pseudocode described above looks like this.
for i in range(epoches):
param_grad = calculate_gradient(loss_function, [examples])
param = param - learning_rate * params_grad
For each update we need to walk through all these examples, if there are millions of them, the computation cost would be a problem, let alone there usually are several epochs of updates.
Stochastic Gradient
The inefficiency of the batch gradient leads to another strategy that is widely used in deep learning, which is stochastic gradient descent(SGD).
Instead of updating the params based on the gradients of all examples, SGD updates the param after computing the gradient of one example, what particular is the dataset should be shuffled in each epoch.
The poseudocode of SGC looks like this:
for i in range(epochs):
np.random.shuffle(data)
for example in data:
param_grad = calculate_gradient(loss_function , example)
param = param - learning_rate * param_grad
The algorithm is not as complicated as its name implies. Actually, it’s too simple that we may doubt about its effectiveness in convergence. However, it has been shown that when we slowly decrease the learning rate, SGD shows the same convergence behavior as batch gradient descent, the convergence of stochastic gradient descent has been analyzed using the theories of convex minimization and of stochastic approximation.
A simple improvement of SGD is to perform an update for every mini-batch examples, which is called mini-batch gradient. It is a compromise between batch gradient and SGD and is proved effective in practices. The code looks like this:
for i in range(epochs):
np.random.shuffle(data)
for batch in batches(data, batch_size = 50):
param_grad = calculate_gradient(loss_function , batch)
param = param - learning_rate * param_grad