Why embedding
Natural language processing systems traditionally treat words as discrete atomic symbols, and this may lead to some obstacles in word preprocessing:
- These encodings provide no useful information regarding the relationships that may exist between the individual symbols.
- Discrete ids furthermore lead to data sparsity. We may need more data to train statistical models successfully.
To address these two problems, word embeddings provide a solution to represent words and their relative meanings densely.
Overview
Embedding derives from Vector Space Models(VSMs), one of its well-known schemes is Tf-Idf weights. VSMs can transfer text documents into vectors of identifies, the fundamental theory they rely on is Distribution hypothesis which states that words that appear in the same contexts share semantic meaning.
VSMs have two main approaches: Count-based methods and predictive methods. Count-based methods compute the statistics of how often some word co-occurs with its neighbor words in a large text corpus and then map these count-statistics down to a small, dense vector for each word. Predictive models directly try to predict a word from its neighbors regarding learned small, dense embedding vectors (considered parameters of the model).
Among all the embedding methods, Glove(Count-based) and Word2vec(Predictive) are the most popular.
Count-based Embedding
GloVe is an unsupervised learning algorithm for obtaining vector representations for words. The main intuition underlying the model is the simple observation that ratios of word-word co-occurrence probabilities have the potential for encoding some form of meaning. It is designed to enable the vector differences between words to capture as much as possible the meaning specified by the juxtaposition of two words.
The project page of glove gives detailed information of how glove vectors are computed and provides several pretrained glove word vectors. As the article highlighted , glove was developed with the following consideration:
The Euclidean distance (or cosine similarity) between two word vectors provides an effective method for measuring the linguistic or semantic similarity of the corresponding words.
Similarity metrics used for nearest neighbor may be problematic when two given words almost always exhibit more intricate relationships than can be captured by a single number.
It is necessary for a model to associate more than a single number to the word pair.
Training GloVe model on a large corpus can be extremely time consuming, but it is a one-time cost. project page of glove also provides some pre-trained word vectors, e.g. glove.6B.zip is word vectors trained from words on Wikipedia, take the first line of this file for example
the -0.038194 -0.24487 0.72812 -0.39961 0.083172 0.043953 -0.39141 0.3344 -0.57545 0.087459 0.28787 -0.06731 0.30906 -0.26384 -0.13231 -0.20757 0.33395 -0.33848 -0.31743 ...
‘’the’’ is followed by 100 floats which are the vector values of this word
We can build a dict whose key is words and value is their glove vector
embeddings_index = dict()
f = open('./glove.6B.100d.txt')
for line in f:
values = line.split()
word = values[0]
coefs = asarray(values[1:], dtype = 'float32')
embeddings_index[word] = coefs
f.close()
When we need to build a embedding layer , we just look up the vectors for input words in the dict.
Word2vec
Word2vec, as illustrated in the first part, is a predictive model for word embedding. There are two main branches of Word2vec, the Continuous Bag-of-Words model (CBOW) and the Skip-Gram model. The two models predict words in a different direction, CBOW predicts target words (e.g. ‘mat’) from source context words (’the cat sits on the’), while the skip-gram does the inverse and predicts source context-words from the target words. Therefore, CBOW treats an entire context as one observation and is compatible with smaller datasets, while skip-gram treats each context-target pair as a new observation and play better with larger datasets.
We will focus on skip-gram as we need to deal with large datasets in most time. Here is the structure of this model.
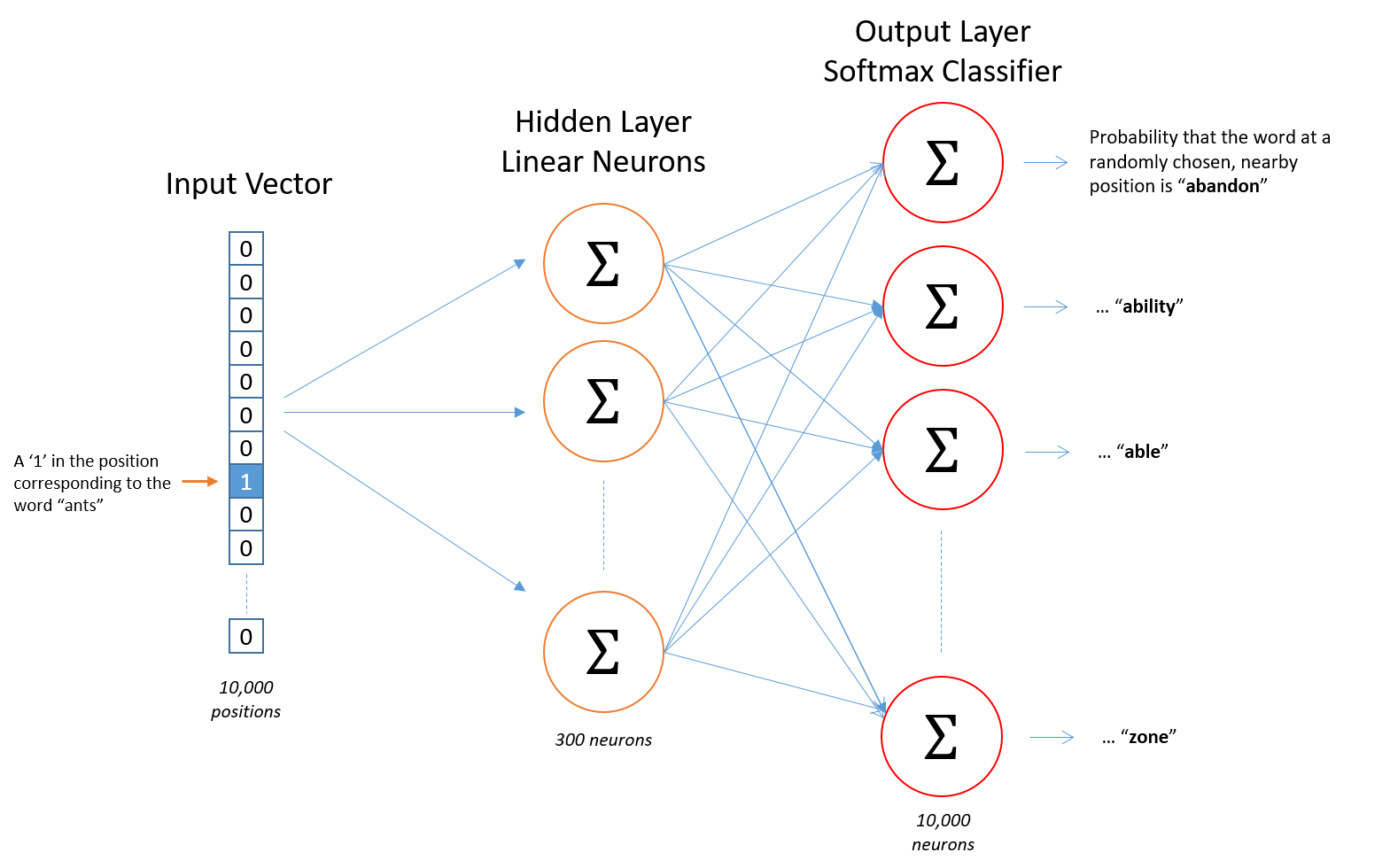
The Skip-gram model is trained like this, Given a specific word in the middle of a sentence (the input word), look at the words nearby and pick one at random. The network is going to tell us the probability for every word in our vocabulary of being the “nearby word” that we chose. The output probabilities are going to relate to how likely it is find each vocabulary word nearby our input word.
The coding example of how to build and train the Skip-gram model can be found here
Next post I will try to use embedding to solve an interesting real world problem.